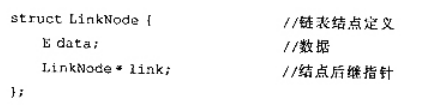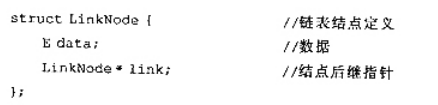题目内容
(请给出正确答案)
题目内容
(请给出正确答案)
[主观题]
设单链表中结点的结构为:已知单链表中结点*q是结点*p的直接前驱,若在*q与*p之间插人结点*s,则
设单链表中结点的结构为: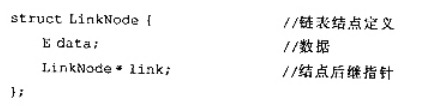
已知单链表中结点*q是结点*p的直接前驱,若在*q与*p之间插人结点*s,
则应执行以下()操作。
A、s->link-p-link;p->link-s;
B、q->link=s;s->link-p:
C、p->link-s->link;s~>link=p;
D、p->link=s;s->link=q;
查看答案

 如果结果不匹配,请 联系老师 获取答案
如果结果不匹配,请 联系老师 获取答案

 更多“设单链表中结点的结构为:已知单链表中结点*q是结点*p的直接…”相关的问题
更多“设单链表中结点的结构为:已知单链表中结点*q是结点*p的直接…”相关的问题